As AI rapidly evolves, organizations everywhere are looking for the smartest ways to leverage these technologies for real-world impact. At nowtec solutions, we are not just watching this revolution, we are hands-on, exploring, testing, and deploying the latest Large Language Model (LLM) solutions for our clients. In this article, we break down two of the most talked-about approaches in training LLMs: Retrieval-Augmented Generation (RAG) and fine-tuning.
What Is RAG (Retrieval-Augmented Generation)?
RAG is a practical approach to making your AI smarter by connecting it directly to your organisation’s unique knowledge base. Think of it as a way to supercharge your LLM with all the information scattered across PDFs, internal websites, Word documents, notes, or even structured and semi-structured datasets.
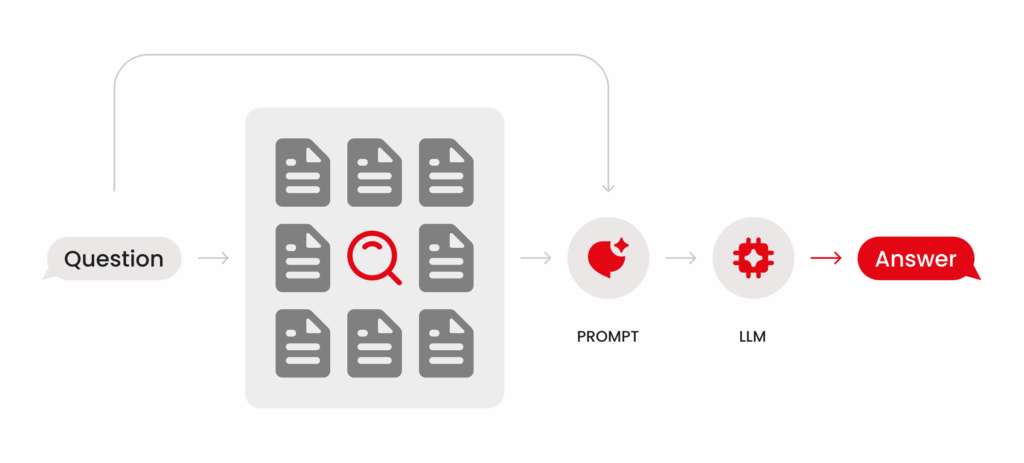
How does it work?
- Embeddings: All your documents are transformed into vectors using proven LLM models, like Ollama or OpenAI.
- Vector Storage: These vectors are stored, turning your information into a “searchable” knowledge library.
- Dynamic Querying: Every time you or a team member chat with the AI, the system rapidly sifts through your embedded knowledge, grabs what’s relevant, and feeds it back to the LLM, ensuring responses are grounded in your business context.
Key advantages of RAG:
- Quick to Deploy: No need for lengthy retraining cycles.
- Multi-use: Your embedded data can power various applications.
- Transparent: You can track which documents informed an answer.
- Efficient: Much less taxing on hardware compared to model fine-tuning.
And the best part? The LLM itself remains untouched. You are simply supercharging its capabilities with your own knowledge, whether you are using a cloud-based or in-house setup.
What About Fine-Tuning?
Fine-tuning takes things a step further. Here, you are actually “teaching” the core LLM itself, customizing it for your organization’s needs.

How does it work?
- Start with Open Model Weights: Take a pre-trained LLM (like Llama 3).
- Inject Your Data: You train the model further using your proprietary documents or specialized datasets.
- A Uniquely Adapted Model: The resulting LLM is now tailored expressly for your organization, with responses shaped by both the original training and your unique additions.
Advantages:
- Deep Customization: Perfect for ultra-specific domains (e.g., medical, legal, or highly specialized technical workflows).
- Niche Use Cases: When you need the model to “think” like your industry experts.
Some challenges:
- Requires heavy computing resources (think powerful GPUs and lots of VRAM).
- Every data update can mean a complex retraining cycle.
- Quality control calls for technical, and often, domain, expertise.
Why We Typically Choose RAG
At nowtec solutions, we typically recommend RAG as the go-to approach for most client projects. It lets us move quickly, update knowledge easily, and maintain full transparency into how answers are generated, without bogging teams down in complex infrastructure or never-ending retraining cycles. Fine-tuning is absolutely in our toolkit for clients who need rigorous specialization, but most organizations benefit most from RAG’s adaptability and efficiency.
Want to See This Explained? Watch Vladimir’s Video
Want a deeper, real-world explanation? Watch the video below, where Vladimir, our CTO, walks through these concepts with practical insights and direct examples from our team’s own experiences.
If you are considering RAG, fine-tuning, or a blend of both, or if you want to set up a custom LLM workflow tailored for your business, let’s chat! The nowtec solutions team is here to co-create the right setup for your goals.
{kind=link}
{kind=link}